


时域存算一体AI芯片
清华大学集成电路学院尹首一教授团队在存算一体人工智能(AI)芯片方向取得突破。该团队设计的时域存算一体AI芯片TIMAQ,通过融合时域SRAM存内计算和数字可重构架构,克服了时域计算的高延迟瓶颈,可支持任意量化的神经网络,为设计通用灵活、低功耗、高能效的终端AI芯片提供了一条新的技术路径。2021年9月,该研究成果以“TIMAQ: A Time-Domain Computing-in-Memory-Based Processor Using Predictable Decomposed Convolution for Arbitrary Quantized DNNs”为题发表于集成电路领域顶级期刊IEEE Journal of Solid-State Circuits(JSSC)。
随着深度学习的飞速发展,各种人工智能应用迫切需要部署到终端设备上。单一AI芯片需要有足够高的灵活性以支持多种应用的不同数据位宽神经网络。存算一体芯片通过在存储单元内执行模拟计算,消除了传统纯数字架构中“存储墙”的瓶颈,大幅减少了访存功耗及计算功耗。相比传统电压域或电荷域存算一体芯片,基于脉冲的时域存算一体芯片具有更低能耗,因此时域存算一体(TD-CIM)是实现低功耗、高能效AI芯片的一种优良架构。但TD-CIM仍需解决两个技术挑战:1)由于模拟电路的设计复杂、模拟量受制约因素多,TD-CIM架构灵活性、电路重构性较差,只能支持固定位宽、固定数据流的计算;2)TD-CIM通过时间量执行乘加计算,数据值越大,延迟越高。
TIMAQ通过在TD-CIM外围耦合一套数字辅助计算引擎,完成TD-CIM难以实现的算子,并动态调整TD-CIM的数据流与计算精度,实现了对不同应用和不同性能需求的灵活适配。数字辅助计算引擎包括三种单元:1)卷积拆分单元:将任意量化方式(均匀和非均匀量化)、任意位宽的卷积核片上拆分为多个一比特卷积核,从而支持了任意神经网络计算。同时分离卷积计算中的加法和乘法算子,将乘法复杂度从O(n)减少到O(1)。2)卷积预测单元:通过分析数字电路上接收的TD-CIM实时计算结果,动态调整数据流及TD-CIM上的卷积映射,从而消除冗余计算,减少能耗和延迟。3)TD-CIM精度控制单元:根据应用场景的能耗、延时要求,通过数字电路动态选择TD-CIM中脉冲量化的最优频率,自适应地调整TD-CIM的计算精度,满足不同应用对功耗或延时的需求。通过数字辅助计算引擎和TD-CIM的高度配合,TIMAQ实现了高灵活性,可以支持任意神经网络、适配不同应用场景的性能需求。TIMAQ芯片架构和显微照片如图1所示,采用TSMC 28nm工艺实现,芯片面积7.21mm2,可支持1~8b的均匀和非均匀量化的神经网络,峰值能效可达到2.4~152.7 TOPS/W,是之前加速非均匀量化、均匀量化神经网络AI芯片能效的8.87~80.69、1.52~13.83倍。
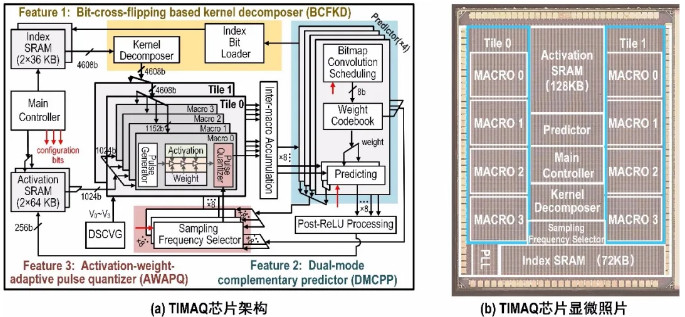
图1. TIMAQ芯片架构和显微照片。
详情请点击论文链接:https://ieeexplore.ieee.org/document/9491142
来源:半导体学报微信公众号

