


链式张量存算一体AI芯片:以“计算换存储”打破AI模型“访存墙”
清华大学集成电路学院魏少军教授、尹首一教授团队在存算一体人工智能(AI)芯片方向取得突破。该团队设计的存算一体芯片TT@CIM,以彻底消除AI算法模型参数访存为目标,突破传统AI芯片固有的“访存墙”瓶颈,为系统级高能效存算一体AI芯片的设计提供了一条新技术路径。2022年8月,该研究成果以“TT@CIM: A Tensor-Train In-Memory-Computing Processor Using Bit-Level-Sparsity Optimization and Variable Precision Quantization”为题发表于集成电路领域顶级期刊IEEE Journal of Solid-State Circuits (JSSC)。
传统冯·诺依曼体系结构所带来的“访存墙”问题日益严重,计算单元与存储单元间频繁的数据搬移造成了大量能耗。存内计算(CIM)单元将计算与存储电路合二为一,被视为打破“访存墙”的有效途径,因而在能效方面具有天然的理论优势。随着人工智能算法日渐复杂,AI算法模型参数量呈爆炸式增长,大幅超过当前AI芯片内所能集成的SRAM-CIM模块容量。因此,当前所设计的存算一体AI芯片仍然需要依赖从片外DRAM读取AI算法模型参数。如图1所示:(1)DRAM的访存能耗约为10 pJ/bit,而SRAM-CIM一次计算的平均能耗约为87 fJ;(2)当考虑DRAM访存能耗时,存算一体AI芯片一次计算将消耗约3741.6 fJ的能量,其相较于基于传统冯·诺依曼体系结构的AI芯片仅能实现1.04倍的能效提升,远低于SRAM-CIM宏单元的能效提升率。可见,AI算法模型的片外访存极大制约了存算一体所带来的能效收益。
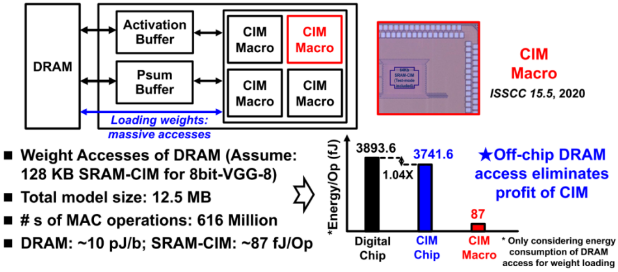
图1. 当前存算一体AI芯片仍然面临“访存墙”瓶颈。
为了在系统级层面彻底消除“访存墙”瓶颈,彻底释放CIM所具备的“计算能耗低”的特性,TT@CIM采用了“计算换存储”这一思想,如图2所示:(1)通过张量链(Tensor-Train, TT)算法,原始AI模型被分解为一系列四维核心张量Gκ∈Rrκ-1×rκ×mκ×nκ, κ = 1, 2, ... , d,相较于原始模型,Gκ具有极小的参数量,可被CIM芯片完全存储于片上;(2)在TT@CIM中,常规CIM芯片中的“向量-矩阵乘法(VxM)”被转化为“向量-张量链乘法(VxTT)”,相较于原始AI推理过程,向量-张量链乘法运算量有所增加;(3)对于一次矩阵向量积计算,图2解析地给出了“计算换存储”前后的模型参数量和计算量。对于完整的一个网络,以Wide-ResNet-20网络为例,其原模型有3.91 M个参数,其无法完全存储于TT@CIM中。通过TT算法处理,仅需存储119.5 K个参数,以增加约11倍计算量的代价,换取了约34倍模型参数量的下降,进而可以完全存储在TT@CIM所集成128 KB SRAM-CIM中,避免了约4 MB的片外访存。
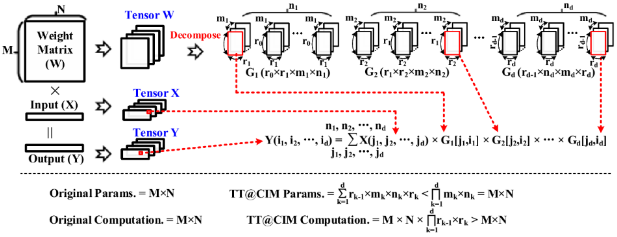
图2. TT@CIM芯片执行“输入向量-权重张量链-乘积”计算,以减少AI模型参数量。
TT@CIM以更多的计算换取了模型参数存储量的大幅减少,与常规CIM芯片中的VxM计算相比,其执行的VxTT计算具有大量-小尺寸核心张量-链式乘法的特点。在存内计算AI芯片上实现VxTT计算主要有以下难点:(1)小尺寸:原始AI模型中“矩阵向量积”的乘加计算并行度大,但其被分解后所产生的四维核心张量的每一维度数据量很小,通常远低于CIM单元内部的乘加计算并行度。因此,存储核心张量并在内部执行链式乘法计算将造成CIM资源利用率的下降;(2)大量:在推理过程中每次生成一个输出数据,TT@CIM都需要完整地执行一次张量链式乘法运算,带来了乘法计算的显著增加,如何进一步优化CIM单元计算能耗,是实现高能效的“计算换存储”的关键;(3)链式乘法:CIM单元需要以比特串行的方式激活输入激励,以执行每一级链式乘法计算。因此,CIM单元的运行时间会随着张量链式乘法长度而线性地增加,从而延长全局计算时间。
针对这三大“计算换存储”难点,TT@CIM芯片创新地设计了(1)四维核心张量链式乘法-存内计算-维度匹配的计算数据流架构:重塑高维链式乘法计算以匹配单个CIM宏单元的乘加计算并行性,提升硬件利用率1.6-5.0倍;(2)挖掘数据复用与乘法融合方法减少了乘法计算11-308倍。同时,TT@CIM基于位级稀疏机制优化CIM电路计算功耗,并利用混合数据编码方式提升AI算法中参数的位级稀疏度,降低了13%-15%的芯片能耗;(3)对链式乘法中的输入激励数据采取多精度混合量化方案,对分别为异常值和正常值的激励数据采用不同的量化精度,缩减了激励数据的平均量化位宽,从而降低CIM的位串行输入周期,使芯片吞吐性能提升了10%-20%。
图3展示了TT@CIM芯片的架构、显微照片、测试性能,芯片的流片工艺为28 nm CMOS,面积为8.97 mm2。TT@CIM芯片打破了AI模型的访存瓶颈,使用ResNet-20,Wide-ResNet-20,LSTM (Neuron: 57600-to-256) 三个AI模型的测试显示,执行VxTT计算仅需分别存储52.2 K,119.5 K,11.6 K个参数,分别地减少了约5.6倍,50.1倍, 4954倍的参数量,其均可分别地完全存储在芯片内部所集成的128 KB SRAM-CIM中。通过“计算换存储”,TT@CIM芯片最多可以避免约55 MB的片外访存和43倍的访存能耗。最终,在INT4的计算精度下,TT@CIM芯片峰值能效为691.1 TOPS/W,相比同期发表的国际相关工作提升5.9-15.5倍。
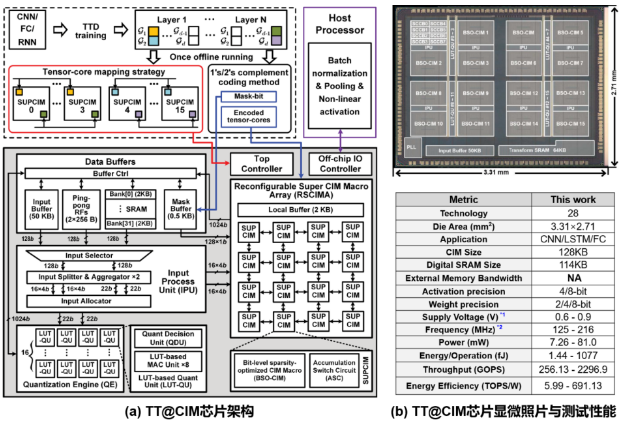
图3. TT@CIM芯片架构、显微照片、测试性能。
来源:半导体学报

